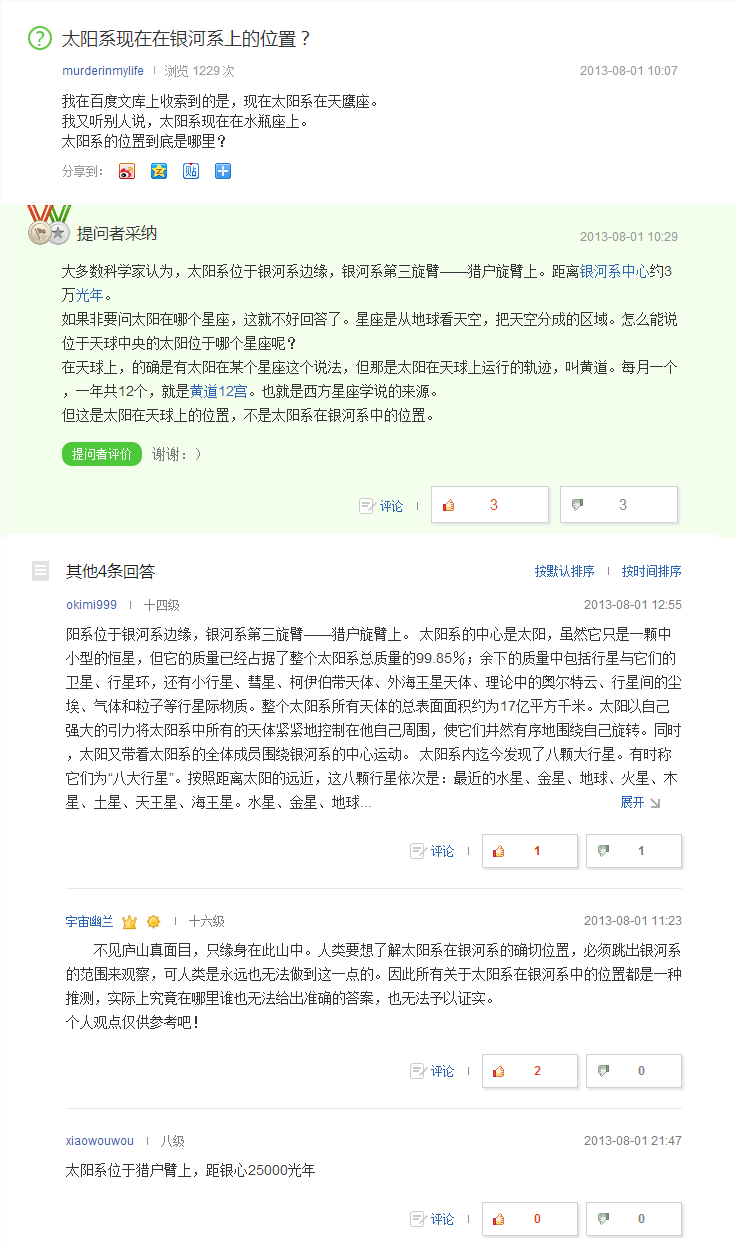
ABOUT ME
Liang Pang - 庞亮
PhD Student
CAS Key Laboratory of Network Data Science and Technology
Institute of Computing Technology, Chinese Academy of Sciences
PROBLEM
Community question answering (CQA) sites have become very popular in recent years [surdeanu2008learning]. Information seekers post their questions on the CQA website and other users can give some replies to the question. Therefore, it is valuable if we can automatically select the best answer from the candidate answers.
For example:

MOTIVATION
Recently, deep learning methods has been applied to this task and gain state-of-the-art performances. Most existing deep models [yu2014deep,qiuconvolutional] are directly using similarities between question and answer by their individual sentence embeddings, obtained by convolutional sentence model (CSM). Such deep models are effective in solving the mismatching problem, therefore they usually work well in distinguishing the best answers of one question with those of other questions. However, the information is usually limited in the descriptions of question, and there is always some lexical gap between question and answer in the application of CQA. These issues make the above deep learning approach far from solving the problem of selecting the best answer from the candidates with respect to one question.
In this paper, we propose a novel deep architecture, namely SPAN, to tackle the above challenges. The main idea comes from the assumption that similar questions usually have similar answers. Based on the above assumption, we can better understand a question with its similar questions' best answers, defined as support answers in this paper. We can see that support answers provide additional content for a question. Furthermore, the lexical gap between question and answer is largely bridged by using support answers to represent a question. Firstly, a deep model is used to generate the sentence embeddings of the question, candidate answer, and the support answers. Then two similarities are computed, one is between question and the candidate answer, and the other one is between support answers and the candidate answer. Finally, the matching score is produced by combing them. Please note that SPAN is a general architecture where any kind of deep model can be used as the basic component to generate the sentence embedding. In this paper, we use CSM as an example to facilitate the study.
MODEL
In this section, we introduce our new deep architecture for CQA, namely SPAN. The basic component of SPAN is convolutional sentence model (CSM), see Fig 1A. Please note that SPAN is a general framework, and we can replace CSM to any kind of sentence embedding model, such as RNN [socher2011dynamic] and LSTM [palangi2015deep]. The reason why we use CSM is because it is a common deep model to represent a sentence, and has been widely applied in many related works such as [yu2014deep,qiuconvolutional].
The input of CSM is a sentence , where each word
in
is represented as its word embedding initialed by Word2Vec. Then one dimensional convolution and pooling is then applied to the sentence layer by layer, and a sentence embedding will be generated as the output of CSM.

The architecture of SPAN is illustrated in Fig 1B. Suppose there is a question and a candidate answer
, they are both feeded into a CSM to obtain their sentence embeddings, denoted as
and
, respectively. Simultaneously, we also leverage the support answers to help understand the semantic of the question. Specifically, we use BM25 [robertson2009probabilistic], a common retrieval model, to obtain the similar training questions of the original question. Then their best answers are extracted as the support answers, denoted as
. They are also feeded into CSM to obtain the sentence embeddings
. Based on those above sentence embeddings, we can obtain two kinds of similarities. The first one is between the question and candidate answer, and the second one is between the support answers and the candidate answer. The similarity measure can be any kind of operators, such as Cosine, Bilinear, and Tensor, denoted as
. The matching score is finally produced by combing these similarities, described as follows.
where and
are combining parameters, which are tuned by hand on validation set.
All other parameters, such as word embeddings and weights in convolution, are learned in the training process. Specifically, we use the ranking loss for optimization. Given a training question and its candidate answers
, we denote
as the best answer of
. Then we can construct
pairs, denoted as
, where
. The loss function on each pair is defined as:
EXPERIMENTS
We conduct experiments on Yahoo! Answers dataset to evaluate our SPAN. The data set contains 142,627 questions and their candidate answers. We first filter out the questions which only contain one candidate answer or have less then three similar questions. The remaining 123,032 questions are then splitted into three set, training, validation, and testing set, which contains 98,426, 12,303, and 12,303 questions, respectively.
In testing set , a ranking list of the candidate answers are obtained according to the descending order of the matching scores. The evaluation metrics of our experiments are P@1 and MRR. Since each question only has one best answer, the two evaluation measures are of the following forms.
| Model | Random | BM25 | CSM | SPAN | SPAN-SA |
|---|---|---|---|---|---|
| P@1 | 25.1 | 39.4 | 47.6 | 48.5 | 48.3 |
| MRR | 48.4 | 59.9 | 66.6 | 67.2 | 67.1 |
Three baselines are used in our model, i.e.Random, BM25, and CSM. Random indicate the model of directly selecting a random ranking list for evaluation. BM25 indicate the model of using BM25 to calculate the similarity between question and its candidate answers to obtain the ranking list. The parameters of BM25 are set to be and
, which are tuned by grid search on validation set. For SPAN,
and
are set to be equal in our experiments, with other parameters learned automatically. The experimental results are listed in Table 1.
From the results, we can see that SPAN outperforms the three baselines. This demonstrates that the introduction of support answers can largely alleviate the problem of information lack in question description and lexical gap between question and answer, and facilitate the matching process. We also list the results of SPAN by only using the representations of support answers, denoted as SPAN-SA. The results show that it can also beat the three baselines, indicating that support answers themselves can be viewed as good representations for a question in this task.
VISUALIZATION
To visualize what we have learnt, we set to negative Euclidean Distance. The CSM's output as 2 dimension vector, in order to draw it on Cartesian coordinate.

The Red-X denotes Question, Red-Dot denotes Support Answers (we use three Similar Questions). The Green-Dot denotes the Best Answer of this Question and Blue-Dot denotes the other candidate answers.
DISCUSSION
In this paper, we propose a novel deep architecture for CQA, namely SPAN. The main contribution is to introduce support answers to help understand the semantic of a question. Our experimental results show that the architecture performs better than several existing baselines. In future, we decide to test our idea on other more complex models such as Arc-II [hu2014convolutional] and LSTM [palangi2015deep]. We also want to investigate how to design an end-to-end model to automatically involve support answers in the learning process.
REFERENCE
- surdeanu2008learning
- Surdeanu, M.; Ciaramita, M.; and Zaragoza, H. 2008. Learning to rank answers on large online qa collections. In ACL, 719– 727.
- hu2014convolutional
- Hu, B.; Lu, Z.; Li, H.; and Chen, Q. 2014. Convolutional neural network architectures for matching natural language sentences. In Advances in NIPS, 2042–2050.
- palangi2015deep
- Palangi, H.; Deng, L.; Shen, Y.; Gao, J.; He, X.; Chen, J.; Song, X.; and Ward, R. 2015. Deep sentence embedding using the long short term memory network: Analysis and application to information retrieval. arXiv preprint arXiv:1502.06922.
- qiuconvolutional
- Qiu, X., and Huang, X. Convolutional neural tensor network architecture for community-based question answering.
- robertson2009probabilistic
- Robertson, S., and Zaragoza, H. 2009. The probabilistic rele- vance framework: BM25 and beyond. Now Publishers Inc.
- socher2011dynamic
- Socher, R.; Huang, E. H.; Pennin, J.; Manning, C. D.; and Ng, A. Y. 2011. Dynamic pooling and unfolding recursive autoen- coders for paraphrase detection. In Advances in NIPS, 801–809.
- yu2014deep
- Yu, L.; Hermann, K. M.; Blunsom, P.; and Pulman, S. 2014. Deep learning for answer sentence selection. arXiv preprint arXiv:1412.1632.